Abstract
Vision-Language-Action (VLA) models have emerged as a promising paradigm for robot learning, but their representations are still largely inherited from static image-text pretraining, leaving physical dynamics to be learned from comparatively limited action data. Generative video models, by contrast, encode rich spatiotemporal structure and implicit physics, making them a compelling foundation for robotic manipulation. But their potentials are not fully explored in the literature. To bridge the gap, we introduce DiT4DiT, an end-to-end Video-Action Model that couples a video Diffusion Transformer with an action Diffusion Transformer in a unified cascaded framework. Instead of relying on reconstructed future frames, DiT4DiT extracts intermediate denoising features from the video generation process and uses them as temporally grounded conditions for action prediction. We further propose a dual flow-matching objective with decoupled timesteps and noise scales for video prediction, hidden-state extraction, and action inference, enabling coherent joint training of both modules. Across simulation and real-world benchmarks, DiT4DiT achieves state-of-the-art results, reaching average success rates of 98.6% on LIBERO and 50.8% on RoboCasa GR1 while using substantially less training data. On the Unitree G1 robot, it also delivers superior real-world performance and strong zero-shot generalization. Importantly, DiT4DiT improves sample efficiency by over 10x and speeds up convergence by up to 7x, demonstrating that video generation can serve as an effective scaling proxy for robot policy learning.
Overview of DiT4DiT
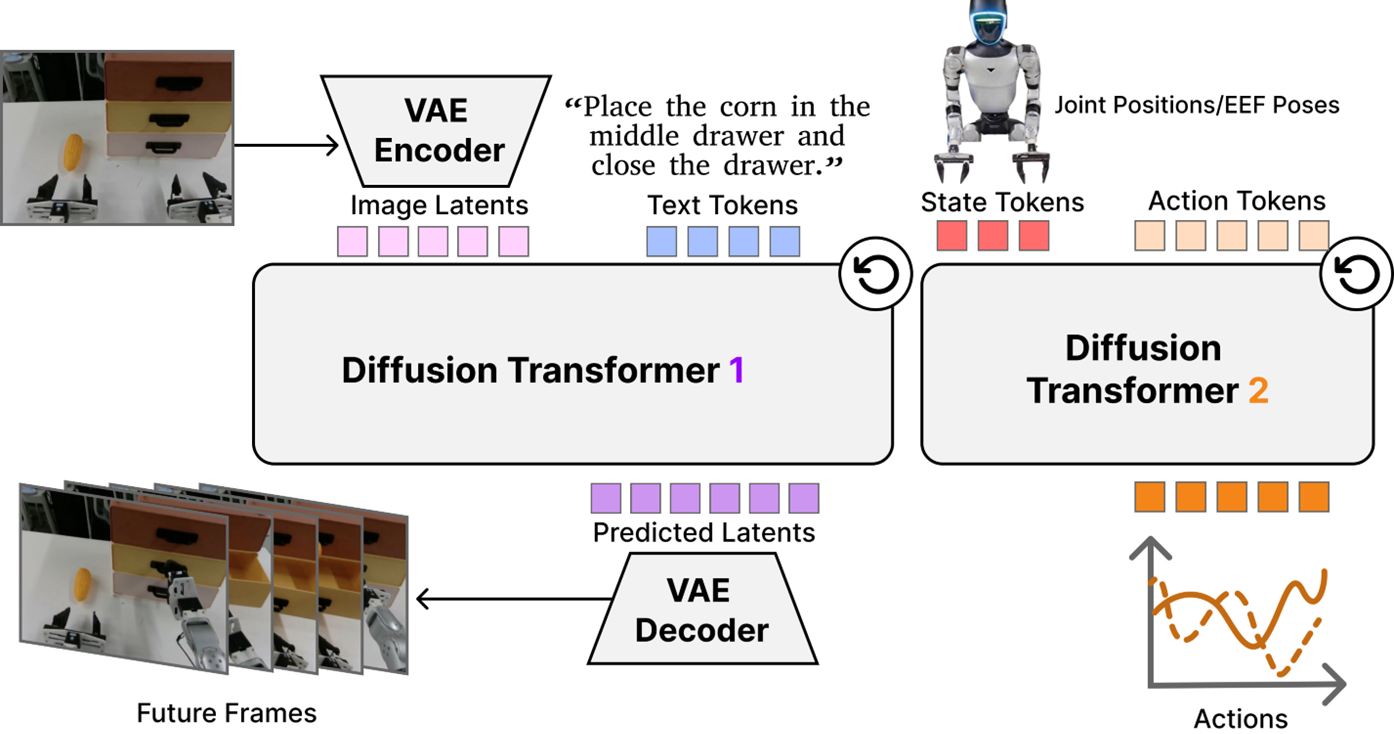
DiT4DiT is an end-to-end Video-Action Model with a cascaded dual-DiT architecture. (a) The Video DiT (initialized from Cosmos-Predict2.5-2B) takes the current observation frames and a language goal, encodes them via a causal video VAE into latent space, and models future visual dynamics via flow matching. A forward hook mechanism intercepts intermediate hidden activations at a fixed flow timestep from a specific transformer layer, converting the generative process into rich, physics-aware visual tokens — without requiring full video reconstruction. (b) The Action DiT takes the extracted visual tokens via cross-attention, along with proprioceptive state embeddings and noisy action trajectories, and predicts a velocity field to generate precise robot action trajectories. (c) A dual flow-matching objective with a tri-timestep scheme jointly optimizes both branches end-to-end, allowing the video branch to learn the full generative trajectory while the action branch performs efficient generative inverse dynamics.
Why Video Generation?
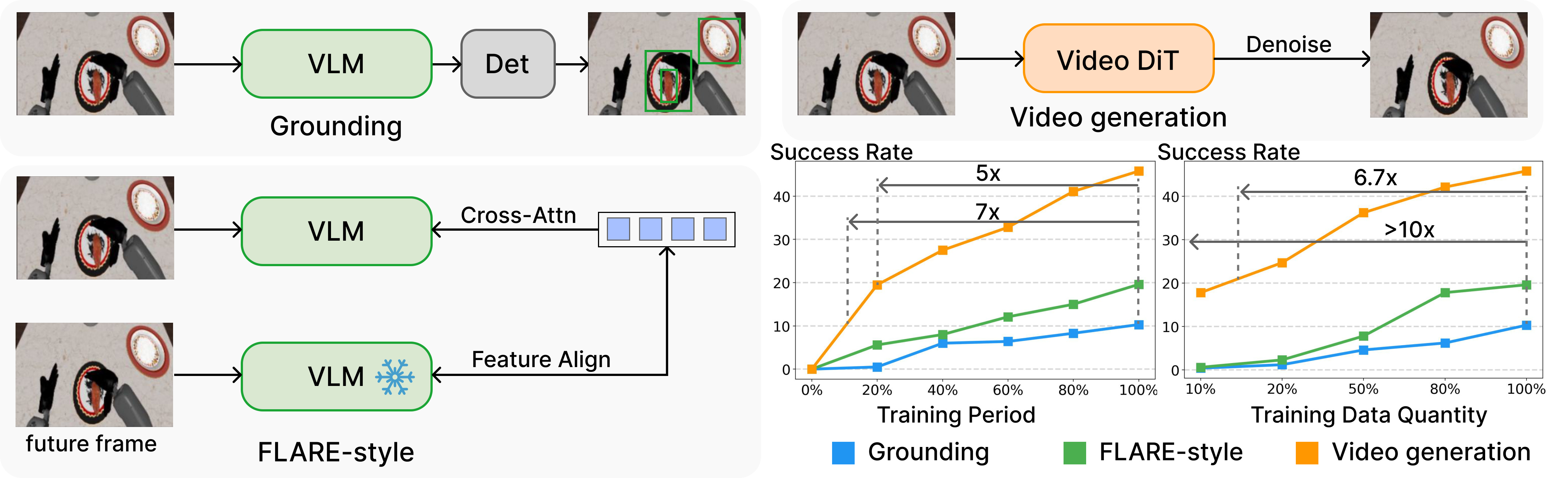
We provide empirical evidence that video generation is a vastly superior, data-efficient unsupervised training objective compared to semantic grounding or VLM-centric latent modeling. Our study compares three proxy objectives: semantic grounding, FLARE-style latent prediction, and video generation. Video generation achieves up to 10× higher data efficiency and 7× faster convergence.
Simulation Results
DiT4DiT achieves state-of-the-art performance on two challenging simulation benchmarks.
LIBERO Benchmark
DiT4DiT achieves 98.6% average success rate across four LIBERO suites, surpassing all baselines including π0.5 (96.9%), CogVLA (97.4%), and OpenVLA-OFT (97.1%). Particularly strong on LIBERO-Long (extended horizon): 97.6%.
| Method | LIBERO-Spatial | LIBERO-Object | LIBERO-Goal | LIBERO-Long | Average |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| CogACT | 92.5 | 92.7 | 91.3 | 74.7 | 87.8 |
| OpenVLA-OFT | 97.8 | 97.8 | 98.0 | 94.8 | 97.1 |
| π0.5 | 98.0 | 98.4 | 96.0 | 95.2 | 96.9 |
| CogVLA | 98.4 | 99.6 | 97.6 | 93.6 | 97.4 |
| Qwen3DiT | 97.0 | 97.2 | 97.8 | 94.2 | 96.6 |
| DiT4DiT (Ours) | 99.2 | 99.2 | 98.4 | 97.6 | 98.6 |
RoboCasa-GR1 Benchmark
DiT4DiT achieves 50.8% average success rate across 24 tasks, surpassing GR00T-N1.5 (41.8%) by 9.0 points and GR00T-N1.6 (40.8%) by 10.0 points. Outperforms Qwen3DiT (36.2%) by 14.6% absolute, confirming that video-generative priors are vastly superior to static VLM priors.
| Task | GR00T-N1.5 | GR00T-N1.6 | Qwen3DiT | DiT4DiT |
|---|---|---|---|---|
| BottleToCabinetClose | 40.0 | 36.0 | 50.0 | 48.0 |
| CanToDrawerClose | 56.0 | 28.0 | 48.0 | 74.0 |
| CupToDrawerClose | 50.0 | 12.0 | 42.0 | 52.0 |
| MilkToMicrowaveClose | 52.0 | 20.0 | 38.0 | 50.0 |
| PotatoToMicrowaveClose | 22.0 | 28.0 | 18.0 | 36.0 |
| WineToCabinetClose | 44.0 | 18.0 | 28.0 | 42.0 |
| FromCuttingboardToBasket | 46.0 | 42.0 | 42.0 | 52.0 |
| FromCuttingboardToCardboardbox | 44.0 | 40.0 | 30.0 | 48.0 |
| FromCuttingboardToPan | 58.0 | 62.0 | 50.0 | 76.0 |
| FromCuttingboardToPot | 48.0 | 60.0 | 44.0 | 62.0 |
| FromCuttingboardToTieredbasket | 28.0 | 48.0 | 36.0 | 50.0 |
| FromPlacematToBasket | 32.0 | 42.0 | 14.0 | 50.0 |
| FromPlacematToBowl | 52.0 | 34.0 | 28.0 | 56.0 |
| FromPlacematToPlate | 42.0 | 42.0 | 40.0 | 32.0 |
| FromPlacematToTieredshelf | 26.0 | 24.0 | 30.0 | 18.0 |
| FromPlateToBowl | 38.0 | 48.0 | 36.0 | 56.0 |
| FromPlateToCardboardbox | 40.0 | 44.0 | 36.0 | 58.0 |
| FromPlateToPan | 56.0 | 48.0 | 34.0 | 68.0 |
| FromPlateToPlate | 50.0 | 66.0 | 44.0 | 58.0 |
| FromTrayToCardboardbox | 36.0 | 42.0 | 48.0 | 38.0 |
| FromTrayToPlate | 54.0 | 52.0 | 44.0 | 56.0 |
| FromTrayToPot | 36.0 | 64.0 | 34.0 | 54.0 |
| FromTrayToTieredbasket | 34.0 | 42.0 | 36.0 | 46.0 |
| FromTrayToTieredshelf | 22.0 | 38.0 | 18.0 | 38.0 |
| Average | 41.8 | 40.8 | 36.2 | 50.8 |
Real-World Results
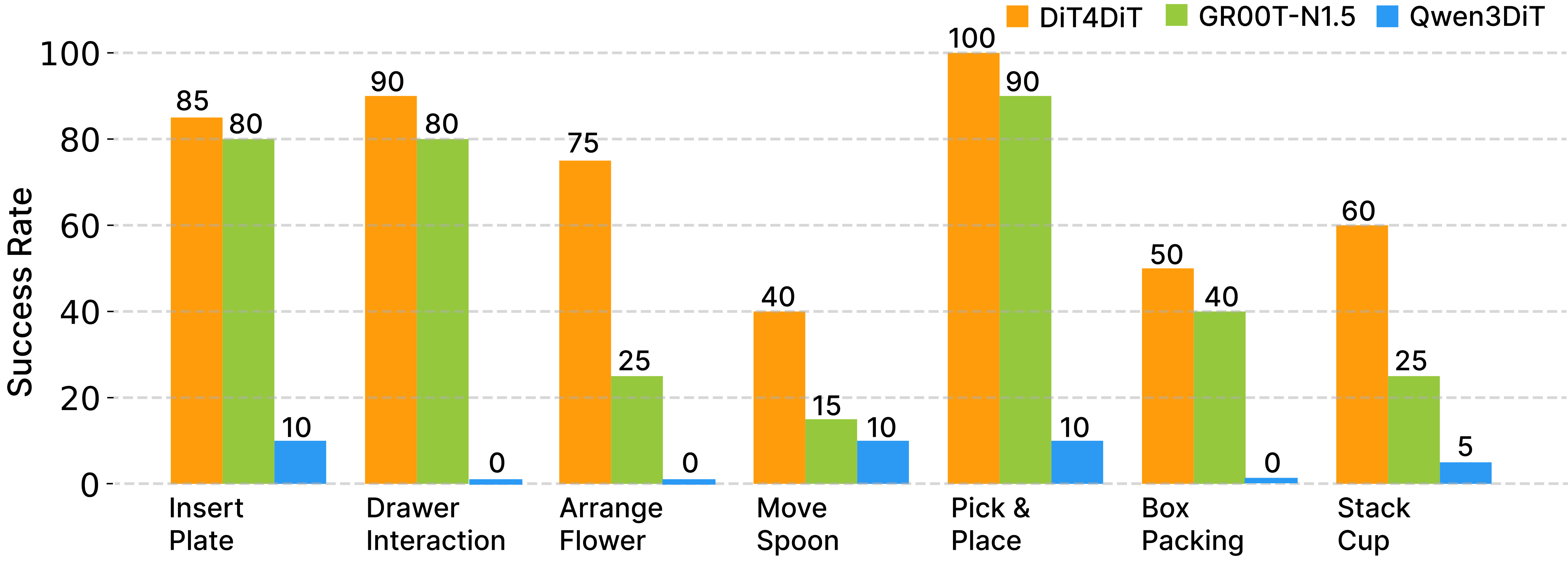
We evaluate DiT4DiT on seven household tasks with the Unitree G1 humanoid robot: pick-and-place, arrange flower, stack cups, insert plate, box packaging, move spoon, and drawer interaction. DiT4DiT comprehensively outperforms both GR00T-N1.5 (pre-trained with more data) and Qwen3DiT across all tasks.
Box Packing (1x speed)
Drawer Interaction (1x speed)
Stack up the Cups (1x speed)
Insert Plate into the Rack (1x speed)
Pick and Place (1x speed)
Arrange the Flower (1x speed)
Move the Spoon (1x speed)
Zero-Shot Generalization
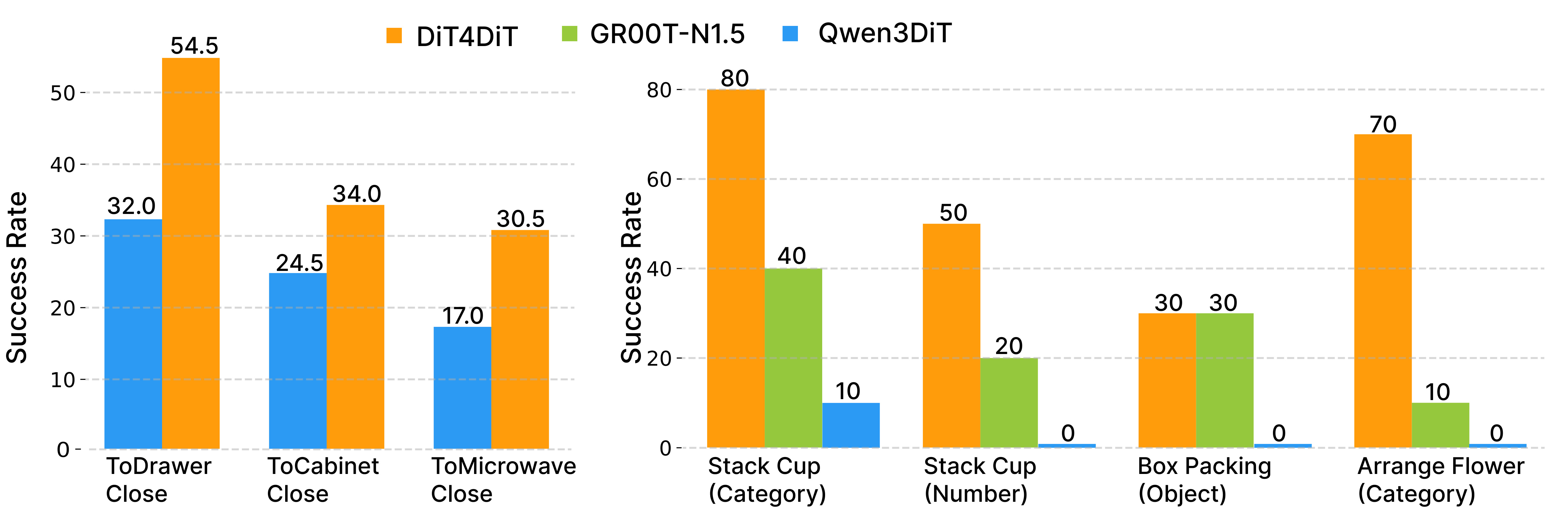
DiT4DiT demonstrates strong zero-shot generalization under severe distribution shifts in both simulation and real-world settings.
Simulation Generalization
In RoboCasa object-substitution tests, DiT4DiT achieves 54.5% on unseen objects vs. 32.0% for Qwen3DiT.
Real-World Generalization
Tested on category changes (unseen cups/vases), object substitution (corn instead of eggplant), and quantity variation (4 cups instead of 3). DiT4DiT achieves 70% on Arrange Flower (Category) vs. 0% for Qwen3DiT and 10% for GR00T-N1.5.

Generated Video Plans
DiT4DiT can optionally generate full video plans showing predicted future dynamics. The video branch produces realistic visual plans that demonstrate the model's understanding of physical dynamics and task-relevant behaviors.

Model Efficiency
| Model | Trainable Params | Deployment Freq. |
|---|---|---|
| GR00T-N1.5 | 2.7B | 13 Hz |
| Qwen3DiT | 2.3B | 9 Hz |
| DiT4DiT (Ours) | 2.2B | 6 Hz |
DiT4DiT is the most parameter-efficient model. While the 6 Hz deployment frequency is lower than alternatives, it is sufficient for real-time closed-loop control, and the superior action quality more than compensates for the lower frequency.